

近日,我院於帥老師課題組在音樂信息檢索領域的研究工作被CCF A類會議AAAI 2024 接收,這也是該課題組在音樂信息領域取得的系列重要進展之一。到目前為止🏖,課題組已經在歌聲旋律提取等音樂信息檢索核心問題取得了重要進展,發表了多篇CCF A/B類會議論文🌒🧑🏻💼。
(一)為了解決歌聲旋律提取中的標註數據稀缺和模型泛化性差的問題,我們提出了一個基於多任務對比學習的半監督歌聲旋律提取模型。

為了克服標註音樂數據稀缺的問題👷🏽♂️,我們提出了一種自洽正則化(self-consistency regularization, SCR)的方法,我們對無標簽的音樂原始數據進行4種轉換,然後將這些信號用於模型的預測🧚🏿♀️。我們不但要求模型能夠一致的預測出旋律線的位置,還要求模型能夠識別出輸入進來的音樂信號做了何種轉換➞。為了克服不同音樂流派在提取歌聲旋律時泛化性能較差的問題,我們提出了一種領域自適應的方法🤹🏿♀️,讓模型能夠學習領域無關的特征用於歌聲旋律提取。最後,我們將上述模塊的損失函數一起進行優化🧑🏿💼,進行多任務學習🐚。我們提出的模型在4個公開數據集上均取得了state-of-the-art的效果,有效解決了歌聲旋律提取中標註數據稀缺🥊🙋♂️、泛化能力差的問題。
該項工作發表於AAAI 2024(CCF A)🫲🏼,計算機沐鸣於帥老師為第一作者🧗🏻,沐鸣娱乐計算機沐鸣為第一單位。
(二)歌聲旋律提取是音樂信息檢索領域的核心問題👨❤️👨。歌聲旋律提取模型在實際應用中,經常被部署在手機等移動設備上。隨著vision transformer在計算機視覺領域取得了巨大的成功,研究人員提出將vision transformer應用在歌聲旋律提取任務上。但是vision transformer巨大的計算量和參數量,對模型在移動設備上的部署帶來了困難。
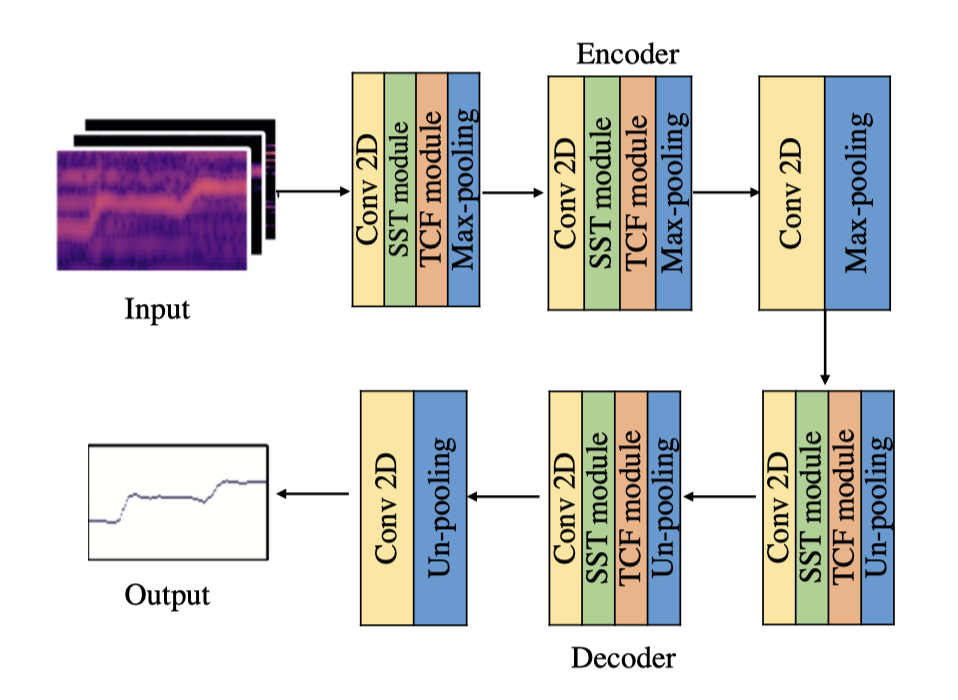
為了克服vision transformer在移動設備部署困難的問題🤹🏿♂️,我們提出了一種可擴展的稀疏transformer模型用於歌聲旋律提取。首先🍳🏋🏽♀️,我們提出了一個稀疏的transformer模型用於歌聲旋律提取,這個模型只需要計算當前幀所在行和列在頻譜上的關聯,極大地降低了計算量和參數量🥪🚴🏿。然後,我們又提出了一個可擴展的稀疏transformer模型,這個模型可以在那些算力稍強的移動設備進行部署,它在稀疏transformer模型的基礎上進一步計算當前幀相鄰幀/頻帶之間的相關性。最後,我們將這個可擴展的稀疏transformer模型與一個輕量化的CNN 模型結合在一起,以彌補transformer訓練收斂慢的缺點🪰。我們提出的模型在3個公開數據上均取得了state-of-the-art效果。有效地解決了歌聲旋律提取模型在移動設備上的部署問題。
該項工作發表於ICASSP 2024(CCF B),計算機沐鸣於帥老師為第一作者,2023級研究生劉駿為學生第一作者,沐鸣娱乐計算機沐鸣為第一單位。