

近日,我院常姍老師課題組在聯邦學習激勵機製領域的研究工作被CCF A類會議INFOCOM 2024接收👟,這也是該課題組在聯邦學習激勵機製領域取得的系列重要進展之一。到目前為止,課題組已經在聯邦學習激勵機製領域取得了重要進展🚴🏻,發表了多篇CCF A/B類會議論文。
在分布式機器學習框架聯邦學習中👩🏻🏭🏇,參與者使用他們的本地數據(隱私敏感)來訓練本地局部模型。這些模型將被傳遞到服務器端並在服務器端進行聚合,從而得出一個全局模型☂️,並下發給各個參與者4️⃣。上述過程會迭代直到全局模型收斂。參與者的數量和參與者數據的質量都會顯著影響最終模型的性能🙇🏻♀️。參與者會因為以下原因不願參與聯邦學習。首先,參與聯邦學習會給參與者帶來巨大的計算和通信開銷🧏🏼,特別是當這些是像手機這樣的低端移動設備時。其次,盡管聯邦學習可以保證參與者訓練數據的私密性,但本地局部模型也可能被用來推斷他們的本地數據🧑🏼💼,威脅到參與者的隱私。因此🎅🏽,設計一種激勵機製進行公平的貢獻評估以及酬勞分配來吸引參與者進行訓練是非常重要的。本研究提出了一種激勵機製方法,該方法考慮以下挑戰因素:
首先,計算夏普利值的時間復雜度是參與者數目的指數級別🔥。在跨設備聯邦學習中會帶來巨大的計算開銷。第二,不可或缺的參與者可能會被錯誤地分配到負的夏普利值,特別是在數據非獨立同分布的情況下。這是因為直接使用損失函數或準確度作為特征函數不滿足作為必要條件的超可加性🏒。第三🤞🏽,不能適應跨設備聯邦學習每輪訓練中參與者的動態變化。現有的方法要求參與者自始至終參與訓練且不能及時得到他們的酬勞,不完全適用於跨設備聯邦學習🩳。
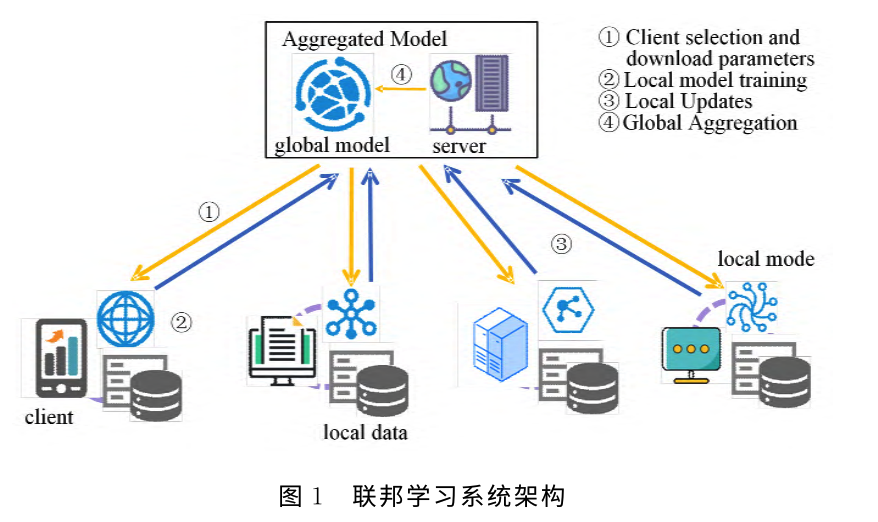
基於上述分析,本研究提出一種基於合作夏普利值的聯邦學習激勵機製方法🧑🏿🎨,用於貢獻評估和酬勞分配。
在這項研究中,我們將聯邦學習視為多次單階段博弈,以充分支持參與者的動態加入和退出,並提出了基於夏普利值的公平高效的貢獻評估機製🦬📈。其基本思想是,參與者的貢獻應按迭代進行評估,而不受參與順序的影響。換句話說🤲🏻,在不同的迭代中👽,與同一組參與者一起更新全局模型的參與者具有完全相同的貢獻🙌🏿。
同時本研究從合作夏普利值入手。這種方法不評估單個參與者對全局模型的影響🪇,而是計算該參與者和所有其他參與者群體合作產生的平均收益🌊。因此,可以消除非獨立同分布數據造成的不合理負夏普利值。
本研究證明具有相同數據分布的參與者在策略上是等價的。這意味著具有相同數量等價參與者的組合也是等價的,因此在合作夏普利值中只需考慮一次👩🏻🚀。為了表示參與者的數據分布🐙,我們使用了局部訓練的梯度,並使用二分K-means聚類方法將參與者分為若幹組👨🏼🚒。我們評估的是參與者組的合作夏普利值,而不是單個參與者的合作夏普利值,這就將計算成本從指數級降低到了多項式級。
表1實驗結果表明🧝🏽,與兩種最先進的近似方法相比(截斷蒙特卡洛采樣TMC💅🏼,組測試GT)🍻,本研究方法實現了高達25倍的提速☆,並將誤差降低了三個數量級(余弦距離CD,歐幾裏得距離ED和最大距離MD)🚴🏿♀️。
表格 1不同算法的近似誤差和時間開銷

研究工作發表在計算機學會推薦A類會議IEEE International Conference on Computer Communications(INFOCOM 2024)上。